
Google Research poslouchá...
Výzkumné oddělení Google Research používá vestavených mikrofonů v počítači, aby snímalo zvuk z okolního prostředí. Vše se snaží analyzovat a zpracovávat, následně se potom chování počítače může měnit podle snímaných dat. Výběr kontextové reklamy podle toho na co se díváte v televizi a nebo co posloucháte u počítače za hudbu.
Konference Euro ITV
![]() Členové týmu Google Research Michele Covell a Shumeet Baluja spolu s Michelem Finkem z Hebrejské University of Jerusalem’s Center for Neural Computation prezentovali minulý týden na konferenci interaktivní televize Euro ITV jeden z nejlepších příspěvků – Social- and Interactive-Television Applications Based on Real-Time Ambient-Audio Identification [pdf, 681 kB]. Aplikace sociální a interaktivní televize založené na identifikaci okolního zvuku v reálném čase.
Členové týmu Google Research Michele Covell a Shumeet Baluja spolu s Michelem Finkem z Hebrejské University of Jerusalem’s Center for Neural Computation prezentovali minulý týden na konferenci interaktivní televize Euro ITV jeden z nejlepších příspěvků – Social- and Interactive-Television Applications Based on Real-Time Ambient-Audio Identification [pdf, 681 kB]. Aplikace sociální a interaktivní televize založené na identifikaci okolního zvuku v reálném čase.
Deseti stránkové PDF získalo získalo také ocenění best paper award. Obsahem jejich příspěvku jsou čtyři aplikace pro hromadnou personalizaci. Bylo použito zvuku zapnutého televizoru snímaného v počítači integrovaným mikrofonem. Studie nepočítá s žádným propojením televize a počítače v blízké budoucnosti. Testy proveditelnosti zahrnovaly jak ruchy při běžné konverzaci v pokoji, tak i vyhodnocení v prostředí klasického obývacího pokoje.
Odposlech počítačem
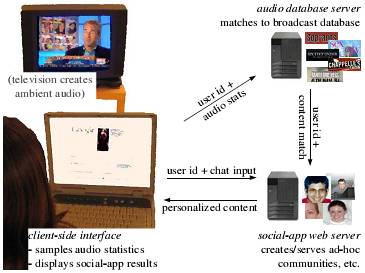 Do počítače je zaznamenáván zvuk v prostředí, následně je statistiky zpracován a odeslán na server se sociálním softwarem. Podle nasbíraných dat je zpět ke klientovi zaslán kontextový a interaktivní obsah. V případě, že uživatel sleduje nějaký díl seriálu a činí tak několik dalších uživatelů, na serveru může vzniknout nová ad hoc komunita. Tato komunita potom má možnost mezi sebou komunikovat přes aplikaci na serveru. Ochrana uživatele spočívá v nevratném statistickém zpracování zvuku v počítači uživatele ještě před odesláním jakýchkoliv informací na server.
Do počítače je zaznamenáván zvuk v prostředí, následně je statistiky zpracován a odeslán na server se sociálním softwarem. Podle nasbíraných dat je zpět ke klientovi zaslán kontextový a interaktivní obsah. V případě, že uživatel sleduje nějaký díl seriálu a činí tak několik dalších uživatelů, na serveru může vzniknout nová ad hoc komunita. Tato komunita potom má možnost mezi sebou komunikovat přes aplikaci na serveru. Ochrana uživatele spočívá v nevratném statistickém zpracování zvuku v počítači uživatele ještě před odesláním jakýchkoliv informací na server.
Záznamu zvuku místo videa bylo použito z několika důvodů:
- videokarta v počítači není samozřejmostí, v počítačích jsou spíše mikrofony
- není vyžadována žádná kalibrace či normalizace obrazu ani nasměrování kamery na obraz televize
- zpracování zvuku vyžaduje méně výpočtů než zpracování videa
A vedle způsobu zpracování byla nastíněna také čtyři možná využití:
Personalizované informační vrstvy
První možností jsou personalizované informace doplňující televizní vysílání. Zatímco sledujete televizní noviny, které informují o Tomu Cruisovi, tak se vám v personalizované informační vrstvě zobrazují doplňkové informace například z módy – jméno návrháře, který navrhl jeho šaty. Nebo údaje týkající se cestování, zdraví, financí či politiky.
Ad-hoc komunity
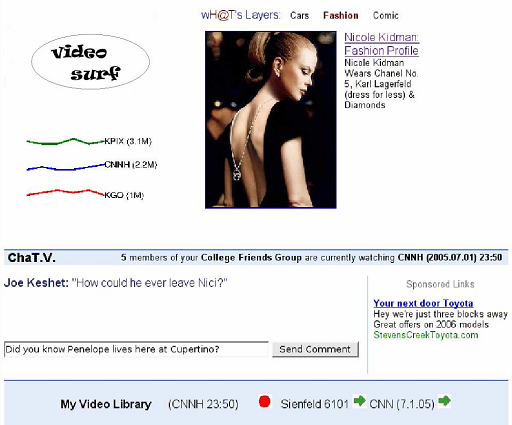 Diskusní fóra týkající se aktuálního zpravodajství nebo televizních seriálů jsou důkazem, že lidi rádi probírají informace z masových médií. Bohužel je velmi těžké říci, s kým je nejlepší tyto zážitky sdílet během vysílání. Na serveru je možné slučovat takové skupiny lidí, kteří sledují právě tentýž televizní seriál a dát jim možnost komunikovat mezi sebou a hned se vyjadřovat k aktuálnímu dění.
Diskusní fóra týkající se aktuálního zpravodajství nebo televizních seriálů jsou důkazem, že lidi rádi probírají informace z masových médií. Bohužel je velmi těžké říci, s kým je nejlepší tyto zážitky sdílet během vysílání. Na serveru je možné slučovat takové skupiny lidí, kteří sledují právě tentýž televizní seriál a dát jim možnost komunikovat mezi sebou a hned se vyjadřovat k aktuálnímu dění.
Komunita se automaticky mění podle toho, co se sbírá z uživatelských počítačů. Není třeba aktualizovat žádné údaje, stejně tak není třeba zjišťovat o který televizní kanál se jedná - stačí přepnout a uživatel se ocitá v jiné komunitní skupině. Tento způsob je zcela odlišný od personalizovaných informačních vrstev, protože umožňuje komentovat aktuální situaci a sdílet ji hned s dalšími uživateli.
Hodnocení popularity v reálném čase
I když již existuje jisté měření popularity televizních kanálů, tak jde o měření zpožděné. Tímto způsobem je možné sledovat popularitu libovolného televizního kanálu v reálném čase. Hodnocení v reálném čase může dát další informace novým uživatelům o tom, co se právě teď nejvíce sleduje. Inzerenti mohou podle rychlé odezvy volit jinou variantu inzerce ze stejné kampaně, pokud je některá varianta málo populární.
Video Bookmarky
Některé americké televizní stanice umožňují opakované sledování vysílaných seriálů na internetu. Umožňují divákům tvorbu jejich oblíbených knihovniček se seriály. Čtvrtá aplikace nabízí vytváření těchto knihovniček bez námahy. Stačí na počítači stisknout tlačítko pro uložení do oblíbených a daný okamžik v pořadu bude automaticky zaznamenán do databáze. Část zaznamenaného zvuku slouží k unikátní identifikaci konkrétní situace v konkrétním pořadu. Stejně jako ostatní oblíbené je možné tento záznam sdílet s ostatními, odkazovat na něj či uložit pro pozdější použití. Oblíbený obsah může být na požádání přehrán, ať již za úplatu nebo spolu s inzercí, která zaplatí náklady poskytovateli obsahu.
Systémové požadavky
Vzorky zvuku byly zaznamenávány každých 5 vteřin, po statistickém zpracování je z nich 415 rámců popsaných 32bitovými deskriptory. Na serveru je uložení dat ještě úspornější. Každý vzorek je komprimován do jednoho 32bitového deskriptoru. To umožňuje uložení ročního vysílání v méně než 1 GB paměti.
Vyhodnocení celého systému
Součástí zprávy je i informace o kvantitativním vyhodnocení celého systému. Pro několik experimentů bylo použito 4 denního záznamu videa. Tři dny byl záznam vysílání jedné televizní stanice a jeden den ještě nějaké jiné stanice. Veškerý videozáznam byl zpracován a všechna opakovaná místa označena (ať již šlo o nějakou inzerci a nebo upoutávku na nějaký film či seriál). Na celém záznamu bylo prováděno testování s 5 sekundovou a 10 sekundovou délkou záznamu. Až na případ dotazů s délkou 5 vteřin překračovala spolehlivost 90 %. A při 5 sekundovém záznamu dělaly problémy pouze místa bez zvukového doprovodu.
Protože jde o technologii, která se připravuje k nasazení do běžného života, bylo provedeno testování typického obývacího pokoje s partnerským sledováním televize. Partneři sedí vedle sebe, zatímco jeden z nich sleduje pořad, tak druhý občas nějakou část komentuje. Jejich vzdálenost od mikrofonu je menší než od televize. Tady již byla spolehlivost zpracování zvuků mnohem horší. Nicméně i přes špatné možnosti rozpoznávání bylo dosaženo 100% spolehlivosti zobrazovaných dat. Pokud nebyla spolehlivost rozpoznávání dostatečně velká, tak se nezobrazovala žádná kontextová informace.
Budoucnost rozpoznávání zvuku
Pokud bude systém upraven tak, aby při jeho použití bylo dosaženo uživatelem akceptovatelné bezpečnosti ukládání dat, pravděpodobně se jej dočkáme. Podobně jako snímání televizního zvuku v počítači je možné implementovat podobnou funkcionalitu do mobilních telefonů, PDA či jiných přenosných zařízení. Jedná se zatím o prezentaci velmi zajímavých badatelských výzkumů a před nasazením do praxe bude třeba ještě provést mnoho dalších kroků.
S větší chytrostí podobných systému je třeba dávat mnohem větší pozor při jejich používání. Dat uložených na serveru bude přibývat, poroste jejich hodnota jak pro provozovatele, potencionální inzerenty, také i pro hackery a následné zneužití.
Google Research Blog - Interactive TV: Conference and Best Paper
Tip: Krátké zprávy a zajímavosti (rychlý přístup https://kryl.info/kratce)
Související
- Vláda chce data - Google říká NE (21. 01. 2006 20:28)
- Posuzování v okamžiku (18. 01. 2006 22:10)
- 10 pravidel firmy Google (05. 12. 2005 21:03)
- Tvorba sebeobranných webových aplikací (01. 08. 2005 08:09)
- Internetové trendy - Web 2.0 (09. 10. 2004 20:25)
- Personalizované vyhledávání (03. 08. 2004 20:54)