XML se poslední dobou stává klíčovou technologií v dalším vývoji na Internetu a nejen tam. Nabízí nám uživatelskou přívětivost (čitelnost pro člověka bez jakéhokoliv zpracování) a výhody při výměně dat na jakékoliv úrovni (ať už mezi aplikacemi a nebo mezi různými systémy).
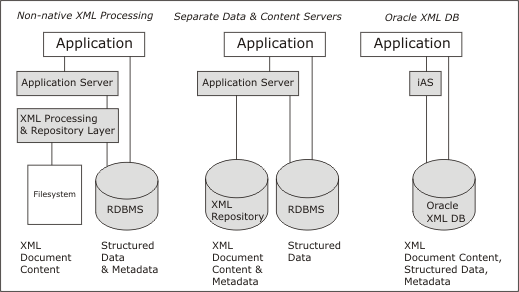
Dnes jsou aplikační data a veškerý obsah internetových prezentací úkládán buď v relačních databázích a nebo přímo na disku jako soubory, případně pomocí kombinace obou zmíněných přístupů. A XML je používáno většinou jako výsledek generovaný z databáze nebo z filesystému. Ačkoliv množství dat, která jsou přenášena jako XML a zpracovávána, čím dál víc roste jejich efektivní uložení se zatím moc často neobjevuje. Tento trend si Oracle uvědomil a ve verzi 9.2 nabízí plnou podporu XML. Základní XML datový model podel standartů W3C, nové metody přístupu a dotazování. Tuto část nazval Oracle XML DB a měla by nabízet všechny výhody relačních databází a technologie XML najednou. Jejich podrobnější popis naleznete v následujícím textu.
Dnešní uživatelé mají dvě možnosti přístupu k datům. Buď je ukládat jako strukturovaná do tabulek a přímo do databáze a nebo jako nestrukturovaná do souborů nebo položek typu BLOB. S tím jsou ale nuceni ve svých aplikacích k těmto datům přistupovat pomocí dvou typů přístupu (pro strukturovaná a nestrukturovaná). XML DB nám umožňuje ukládání obou typů dat pomocí standartního datového modelu W3C XML. Umožňuje transparentní přístup pomocí XML a SQL. Je možné provádět XML operace nad daty z tabulek a SQL operace nad XML daty. Přístup ke XML datům je možný pomocí částečných operací update, insert, indexování, vyhledávání, několikanásobných pohledů na data a spravování dokumentů pro vnitřní potřebu nebo pro veřejné použití.
Zatímco relační databáze nám umožnovaly vysoký komfort pro správu dat, komfort pro správu obsahu nebyl tak vysoký. Pokud ale pracujeme s XML daty tyto možnosti se nám otevírají. Tato služba se nazývá XML Repository. Nabízí nám centralizovanou správu obsahu. Můžeme mít obrovské množství objednávek jako XML soubory, rozsáhlý technický manuál zaznamenaný v XML, soubor žádostí o pojištění zpracovávané v XML. Hlavní výhodou Repository je organizování obsahu, okomentování obsahu pro jeho rychlejší vyhledávání a správa složitých závislostí a vztahů mezi daty. XML DB nabízí takové funkce uvnitř Oracle databáze - rozmisťování do složek, řízení přístupu, FTP a WebDAV protokol se správou verzí. Všechny tyto přístupy nám budou umožněny, pokud data uložíme přímo do databáze Oracle.
XML DB můžeme rozdělit do dvou hlavních částí. XMLType - poskytující přirozené uložení XML a možnosti dotazování jako známe z SQL. XML Repository, která nám umožňuje třídění do složek, řízení přístupu, správu verzí, atd. pro zdroje XML. Nyní se probereme obě části více z blízka.
XMLType jako datový typ umožňuje ukládání XML dat, může být použit jako typ sloupce tradiční databázové tabulky. Nabízí nám několik užitečných metod jak s tímto obsahem pracovat. Pro ukládání je možné zvolit ze dvou možností - LOB a nebo objektově-relační reprezentace. Uložení jako LOB nám zachová přesnou reprezentaci dokumentu (včetně všech whitespace znaků) zatímco v druhém případě se bude blížit reprezentaci DOM (Document Object Model). Tato přesná reprezentace je dána díky udržování informací, které většinou SQL nebo JAVA objekty nezajišťují:
Další výhody XMLType:
Další částí je internetový sklad pro správu XML dat a dokumentů. Hlavní části zahrnují:
Mějme nejaký objednávkový formulář uložený v XML jako jeden sloupeček tabulky. Datová struktura pro tento sloupec bude omezena při vytváření tabulky specifikováním XML Schematu při příkazu CREATE TABLE.
CREATE TABLE xml_order ( info XMLTYPE ) XMLSCHEMA 'http://www.oracle.com/xdb/orderSchema.xsd' ELEMENT 'PurchaseOrder';
orderSchema.xsd vytvoříme pomocí populárního editoru XMLSchematu XML Spy od firmy Altova Corporation. XML dokument budeme chtít ukládat jako objektově-relační model přímo v databázi, abychom měli zachovanou i možnost vytvoření DOM modelu.
<xs:schema xmlns:xdb="http://xmlns.oracle.com/xdb" xmlns:xs="http://www.w3.org/2001/XMLSchema" version="1.0" xs:targetNamespace="xdbPurchaseOrder"> <xs:complexType name="ActionsType" xdb:SQLType="XDBPO_ACTIONS_TYPE"> <xs:sequence> <xs:element name="Action" maxOccurs="4" xdb:SQLName="ACTION"> <xs:complexType xdb:SQLType="XDBPO_ACTION_TYPE"> <xs:sequence> <xs:element ref="User"/> <xs:element ref="Date"/> </xs:sequence> </xs:complexType> </xs:element> </xs:sequence> </xs:complexType> <xs:complexType name="RejectType" xdb:SQLType="XDBPO_REJECTION_TYPE"> <xs:all> <xs:element ref="User"/> <xs:element ref="Date"/> <xs:element ref="Comments"/> </xs:all> </xs:complexType> <xs:complexType name="ShippingInstructionsType" xdb:SQLType="XDBPO_INST_TYPE"> <xs:sequence> <xs:element ref="name"/> <xs:element ref="address"/> <xs:element ref="telephone"/> </xs:sequence> </xs:complexType> <xs:complexType name="LineItemsType" xdb:SQLType="XDBPO_LINEITEMS_TYPE"> <xs:sequence> <xs:element name="LineItem" type="LineItemType" maxOccurs="unbounded" xdb:SQLName="LINEITEM"> </xs:sequence> </xs:complexType> <xs:complexType name="LineItemType" xdb:SQLType="XDBPO_LINEITEM_TYPE"> <xs:sequence> <xs:element ref="Description"/> <xs:element ref="Part"/> </xs:sequence> <xs:attribute name="ItemNumber" type="xs:integer" xdb:SQLName="ITEMNUMBER" xdb:SQLType="NUMBER"/> </xs:complexType> <!-- xdb:tableProps="varray(sys_xmldata.lineitems.LineItem) store as table PO_LINEITEMREFS" --> <xs:element name="PurchaseOrder" xdb:SQLType="XDBPO_TYPE" xdb:defaultTable="PURCHASEORDER"> <xs:complexType> <xs:sequence> <xs:element ref="Reference"/> <xs:element name="Actions" type="ActionsType" xdb:SQLName="ACTIONS"/> <xs:element name="Reject" type="RejectType" minOccurs="0" xdb:SQLName="REJECTION"/> <xs:element ref="Requestor"/> <xs:element ref="User"/> <xs:element ref="CostCenter"/> <xs:element name="ShippingInstructions" type="ShippingInstructionsType" xdb:SQLName="SHIPPINGINSTRUCTIONS"/> <xs:element ref="SpecialInstructions"/> <xs:element name="LineItems" type="LineItemsType" xdb:SQLName="LINEITEMS"/> </xs:sequence> </xs:complexType> <!-- xdb:columnProps="foreign key (sys_xmldata.userid) references scott.emp(ename)"--> </xs:element> <xs:simpleType name="money"> <xs:restriction base="xs:float"> <xs:fractionDigits value="2"/> <xs:totalDigits value="12"/> </xs:restriction> </xs:simpleType> <xs:simpleType name="quantity"> <xs:restriction base="xs:float"> <xs:fractionDigits value="4"/> <xs:totalDigits value="8"/> </xs:restriction> </xs:simpleType> <xs:element name="User" xdb:SQLName="USERID" xdb:SQLType="VARCHAR2" xdb:defaultTable=""> <xs:simpleType> <xs:restriction base="xs:string"> <xs:length value="10"/> </xs:restriction> </xs:simpleType> </xs:element> ... <xs:element name="PONumber" xdb:SQLName="PONUMBER" xdb:SQLType="VARCHAR2" xdb:defaultTable=""> <xs:simpleType> <xs:restriction base="xs:string"> <xs:length value="10"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="SpecialInstructions" xdb:SQLName="SPECIALINSTRUCTIONS" xdb:SQLType="VARCHAR2" xdb:defaultTable=""> <xs:simpleType> <xs:restriction base="xs:string"> <xs:length value="2048"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="name" xdb:SQLName="SHIPTONAME" xdb:SQLType="VARCHAR2" xdb:defaultTable=""> <xs:simpleType> <xs:restriction base="xs:string"> <xs:length value="20"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="address" xdb:SQLName="ADDRESS" xdb:SQLType="VARCHAR2"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:length value="256"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="telephone" xdb:SQLName="PHONE" xdb:SQLType="VARCHAR2"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:length value="24"/> </xs:restriction> </xs:simpleType> </xs:element> ...
Pro použití XML Schema k definici datové struktury ji musíme nejprve zaregistrovat pomocí PL/SQL balíčku. Jediné co je potřeba k registraci schématu je URL adresa k dokumetu schéma definující. XML DB nahraje soubor schématu a provede kompilaci pro efektivní použití za běhu. XML DB také může vytvořit SQL typy a tabulky, indexy a Java class, aby byl připraven k jeho použití.
Překompilované schéma ukládá všechny potřebné informace potřebné k namapování XML elementů a atributů na SQL typy a metody Java Beans, výchozí tabulku ve které budou uloženy konkrétní elementy a datové struktury používané ke správe XMLTYPE objektu v paměti. Programátor buď kontroluje tyto mapovací informace, případně nechá na XML DB aby byly vytvořeno implicitní namapování. Pro specifikaci namapování mohou být přímo do schématu přidány doplňkové atributy. Například: Základní schéma:
<xsd:attribute name="customerID" type="decimal"/>by s doplněnými informacemi vypadala:
<xdb:attribute name="customerID" type="decimal" SQLname="customer_id" SQLtype="number" JavaType="int"/>
Místo toho, aby XML DB hledalo namapování všech elementů samo dodefinujeme tato spojení sami. Všechny atributy v SQL objektu musí být namapovány na nějaký XML element. Je možné nadefinovat několik XML map pro tentýž SQL objektový typ registrací několika schémat pro každé mapování.
Až je schéma zaregistrováno v databázi, je celý XML dokument omezen tímto schématem. Při registraci se celé schéma parsuje, kontroluje se jeho správnost, ukládá se do datového slovníku a také se vytváří SQL definice objektu.
CREATE TYPE purchaseOrderItem AS OBJECT ( productName varchar2(2000), quantity integer, price number, partNum varchar2(2000) ); CREATE TYPE purchaseOrderitems as VARRAY(2147483647) of purchaseOrderItem; CREATE TYPE purchaseOrder as OBJECT ( customerName varchar2(2000), orderDate date, shipDate date, items purchaseOrderItems );
XPath umožňuje přístupovou abstrakci od vrcholu úložného modelu. XPath prochází vhnízděné XML elementy podle specifikování výčtu jmen elementů a jejich atributů oddělených lomítky. Pro SQL jsou definovány dva operátory ExtractNode a ExistsNode nad množinou řádků nebo sloupců typu XMLType. ExistsNode testuje objekt typu XMLTYPE zda odpovídá specifikovanému XPath výrazu.
SELECT xml_order FROM orders WHERE EXISTSNODE(xml_order, '//ship_to/state') > 0
ExtractNode vrací další objekt typu XMLTYPE obsahující takovou část XML dokumentu, která je specifikovaná zadaným XPath výrazem. XMLTYPE může být kvůli výstupu převeden na typ VARCHAR nebo CLOB.
SELECT xml_order FROM orders WHERE EXTRACTNODE(xml_order,'//ship_to/state').getClobVal() = 'CA'
Síla XPath abstrakce je v tom, že specifikovaný objekt je úplně izolován od aplikace. Může být uložen jako SQL objekt (s každým elementem a atributem namapovaným na konkrétní rádek či sloupec) nebo jako LOB v originální textové formě.
Pokud Oracle zpracovává dotaz používající sloupec typu XMLTYPE, tak se nejdřív testuje, zda je možné dotaz přepsat do objektově-relační formy.
Například část dotazu z předchozího příkladu:
EXTRACTNODE(xml_order, '//ship_to/state').getClobVal() = 'CA'
by byla přepsána jako:
xml_order.ship_to.state = 'CA'
Obecně výraz obsahující ExtractNode můžeme použít kdekoliv v SQL dotazu, kde jeho použití dává smysl. Můžeme vytvářet indexy typu B-Strom nebo bitmapové, specifikovat relační integritní omezení nebo další typické vlastnosti databáze Oracle.
Na objekty typu XMLTYPE uložené jako LOB můžeme použít index Oracle Text, pokud je instalován. Nastavení indexu urychlí XPath vyhledávání a také hledání podle klíčových slov přes XML objekty uložené v objektově-relační formě.
XML DB nabízí operátor SYS_XMLGEN() pro generování XML dat z libovolného SQL dotazu.
Například dotaz:
SELECT SYS_XMLGEN(null, empno, empname, salary*100, hiredate) AS xml_doc FROM scott.emp e;
nám vygeneruje
XML_DOC ---------------------------------------------- <?xml version='1.0'?> <ROW> <EMPNO>20</EMPNO> <EMPNAME>John</EMPNAME> <HIREDATE>12-20-1999 20:23:23.0</HIREDATE> </ROW> <?xml version='1.0'?> <ROW> <EMPNO>30</EMPNO> </ROW>
dva XML dokumenty
Výhody volání SYS_XMLGEN() místo nějakého nástroje mimo databázový stroj jsou následující:
Můžeme se na objednávkové formuláře dívat také jako na hierarchicky strukturované složky. To má za následek zpřístupnění pomocí stadartních protokolů jako je WebDAV nebo FTP.
XML DB nativně podporuje WebDAV standart. Vytvořený IETF jako rozšíření protokolu HTTP. Je to nejen protokol, ale také umožňuje hledání a správu dat. Umožňuje přístup k datům pomocí jednoduchého zadání URL. Požaduje mít nastaveny základní informace jako jsou datum, vlastník, přístupová práva atp. Podporuje také kolekce, které si můžeme představit jako složky. Přístup je potom možný pomocí standartních nástrojů Windows jako je Průzkumník. Editace pomocí Microsoft Office i s následním uložením zpět na server, ale také s podporou na systémech Mac OS X a Linux.
XML DB umožňuje také přímý přístup pomocí HTTP nebo FTP protokolu. Těmito způsoby lze potom ze serveru nebo na server dostávat data.
XML DB poskytuje standartní Java API rozhraní. Taktéž dnes populární tvorbu aplikací pomocí servletů JSP (Java Server Pages) a XSL/XSPs (XML Stylesheet / XML Server Pages). JSP jsou navržena pro přístup k datům pomocí Java Beans a XSL/XSPs přistupují k datám pomocí implementace DOM API. Oba tyto způsoby přístupu jsou podporovány, jelikož každý z nich má svá pro a proti.
Protože zpracování dat uložených čistě v XML by vyžadovalo vysoké nároky na výkon serveru, bylo nutné zavést mnoho optimalizací, které tomuto nárustu zabrání. S několika hlavními bych vás rád seznámil v následujícím textu.
Výkon dotazování závisí hlavně na dobrém indexování. XPath je mocné při vytváření dotazů, ale ne při všech takto formulovaných dotazech lze použít indexů pro rychlejší zpracování. Proto se používá následujících operací:
Možnosti, kde vidí programátoři Oracle pro další rozvoj indexování pomocí typu XMLTYPE.
Jedním z největších problémů, který lidi mají při použití XML reprezentace, jsou větší nároky na místo pro uložení dat než v případě jiných reprezentací. Některé výzkumy ukazují, že XML reprezentace je tříkrát větší než reprezentace dat jako Java objekt nebo relační tabulka. A to hlavně ze dvou důvodů:
První problém je řešen ukládáním značek do knihovní cache Oraclu, obsahující všechny informace o značkách a schématu. A v dokumentu jsou jen odkazy do knihovny.
Druhý problém je řešen pomocí XOB (XML Object). Ten je uložen v paměti jako C/C++ objekt s vypočteným posunem, místo uložení každého uzlu v dynamické struktuře jako třeba hashovací tabulce. Pomocná data pro uspořádání a neschématická data jsou uloženy odděleně ve vlastní dynamické struktuře. Pro představu volně dostupné parsery dat potřebují na reprezentaci 80 bytů dat na kazdý DOM uzel. Oproti tomu Oracle používá pro uložení jednoho uzlu pouze 20 bytů.
Milan Kryl ]k[